









.svg)






A skill our Node.js Consulting team practices often is the process of breaking down new product requirements into actionable technical requirements. This is one of the most critical capabilities for a developer to learn in order to help their organization swiftly deliver new features to their users. In this post, we’ll talk through the process we use on our projects.
What are “Actionable” Technical Requirements?
When breaking down requirements, we often start with a SWAG. This might be something as simple as:
-
The Product List Service needs to add a new field
-
The Cart Service needs to update validation
While this is a useful jumping-off point, it is not enough for developers to start working on.
In order for technical requirements to be actionable, they need to include 3 things:
-
What changes needs to be made?
-
Where in the code does each change need to be made?
-
In what order do the changes need to be made?
Breaking Down Technical Requirements
This is the general process that our Node.js Consulting team put together about how we go about breaking down technical requirements.
-
Find the source-of-truth for the data
-
Find any business logic (validation, data processing, reading/writing to the database)
-
Find anything “upstream” of the business logic that will also need to change
-
Don’t forget documentation and tests
Example
Let’s run through an example to see how this works in practice.
In this example, we have a set of serverless functions that provide meal recipes:
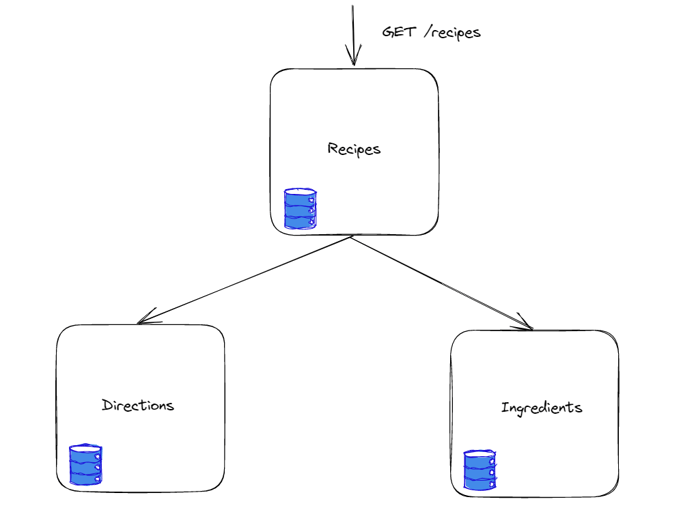
Our new requirement is to add an estimated prep and cook time to each recipe. Let’s follow our steps for breaking down technical requirements.
Find the Source of Truth
We first need to find the source of truth for the data. This will help us better identify the changes that need to be made. In our case, we’re dealing with three tables: recipes, ingredients, and directions. To simplify our demonstration for this blog post, we're going to assume that our database is fully normalized:
-
The
recipestable will contain the recipe name as well asids to link the recipe to theingredientsanddirections -
The
ingredientstable will contain the basic food required for the recipe -
The
directionstable will hold the list of steps to take to combine the ingredients and make the recipe
First, the source of truth for the prep and cook time data needs to be identified. A few changes will need to be made to the schema and codebase. We need to imagine the type of data that will go into our application and make changes accordingly. Here are some examples:
-
“1 cup bell pepper, chopped” – needs to account for time to chop a pepper
-
“mix pancake mix, egg, and milk until smooth” – needs to account for time to mix ingredients
-
“bake for 25 minutes” – needs to account for baking time
To accommodate these scenarios, we’ll plan on making the following changes to the schema:
-
To calculate prep time, we need to take into account the time it takes to prepare each individual ingredient. So the prep time needs to be added to the ingredients schema. We’ll add a new field to specify the time it takes to prepare each ingredient.
-
Similarly, the prep time will be added to the directions, accounting for prep time that includes multiple ingredients, such as combining or mixing.
-
Finally, cooking time will be added to the directions, accounting for the time it takes to bake or otherwise cook the meal.
Identify Business Logic
Next, the business logic will need to be updated. This includes things like handling validation, data processing, and reading/writing to the database:
-
We’ll update the validation logic to ensure that the new prep and cook time fields are valid when creating or updating a recipe.
-
We’ll update the calls to read and write to the database:
cookTimeandprepTimewill be added to thedirections, andprepTimewill be added to theingredients. -
We’ll also update the serverless functions to accommodate our new fields.
Find Upstream Logic
It's also essential to consider any upstream dependencies that may be affected by the changes. In this case, the recipes function needs to be updated to request the new prep and cook time fields from the ingredients and directions functions. The recipes logic also needs to be updated to aggregate the prep time and cook time for each ingredient into a single prep and cook time for the entire recipe.
Don’t Forget the Non-Functional Requirements
In our projects, we like to ensure that everything is documented and tested thoroughly. The changes made to the codebase need to be clearly documented. Migrations will need to be made. Fixture data for tests will need to be created or updated. And finally, all relevant tests need to be updated to account for the new fields. These details take time and should be accounted for when breaking down requirements.
Sequencing
Once you have a list of changes, it is helpful to create a sequence diagram. This can be very helpful for finding requirements that should be broken down further so that more work can be done in parallel. There are many complex tools for doing this kind of sequencing, but it can also be something as simple as cells highlighted in a spreadsheet. For example, this is a sequence diagram for the changes we’ve discussed so far:

Looking at this sequencing, it is obvious that the changes to the recipes function cannot be worked on until the changes to ingredients and directions are implemented and documented. In smaller teams, this might be unavoidable. But in larger organizations where different teams own these different functions, this can be a source of large delays in delivering features.
In these situations, it is useful to break down the update ingredients handler function down into two pieces:
-
Update the schema for the ingredients handler function
-
Update the ingredients handler function
Defining and agreeing on a schema using something like OpenAPI or GraphQL as the first step of a new feature means that the “downstream” team consuming an API can implement changes to their code in parallel with the team making changes to the API itself. This can greatly reduce the overall time to get this feature into the hands of your users.
Conclusion
Breaking down features into actionable technical problems is a key skill for any senior or lead developer. Our Node.js Consulting Team uses a 4 step approach to break down problems on our projects. We start by finding the source of the truth of the data. We then determine the business logic that will need to be updated. Next we look for anything “upstream” of that business logic that will also need to change. Lastly, we find any non-functional changes, such as documentation and tests, that should be updated. Once we’ve used this process to determine all of the required changes, we create a sequence diagram to help determine how we can more efficiently make these changes.
Do you have your own techniques for breaking down technical problems?
We’d love to hear your thoughts! Join our Community Discord to learn about the latest in Node.js Consulting, network with our community, and ask questions! 👋

Need help with your project?
Bitovi can help! Schedule a free consultation, and we’ll show you how, together, we can make it incredible.

